I first met the concept of metastable failure in Marc Brooker’s post. I didn’t understand it well then. Several months later our team develops a new retry mechanism for TiKV. I wrote a simulator program to study the possible impact of the retry system, which reminded me of the metastable failure pattern and guided me to learn more of it. The post describes the story and attach some of my personal take-aways.
Read from a replicated storage system
TiKV is a distribtued data storage system. Data are first partitioned into regions, then each region is replicated over mutiple TiKV servers in a leader-follower manner. Usually the number of replicas is 3.
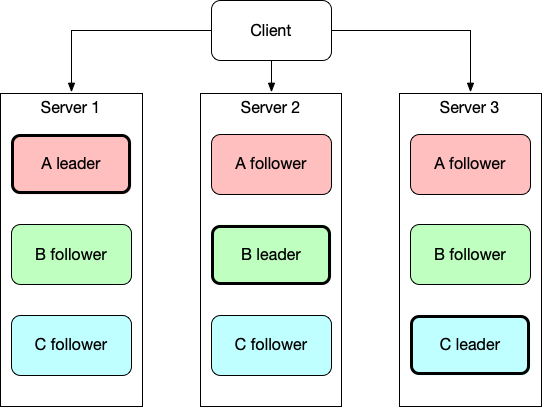
A request can read the data from any of the 3 repilcas, as long as we are sure that data is contained in the replica, which is generally true for stale data. On a single node failure like disk latency jitter, the request can take long time to return. A straightforward idea to optimize this is retry: if a request doesn’t succeed in a certain amount of time, send a retry request to another replica.
This is what we did in TiKV. We implement a new feature: every request is attached with a timeout. The timeout determines a deadline of the request: if the request does not finish before the deadline, the server returns an error to the client and let it retry on other replicas.
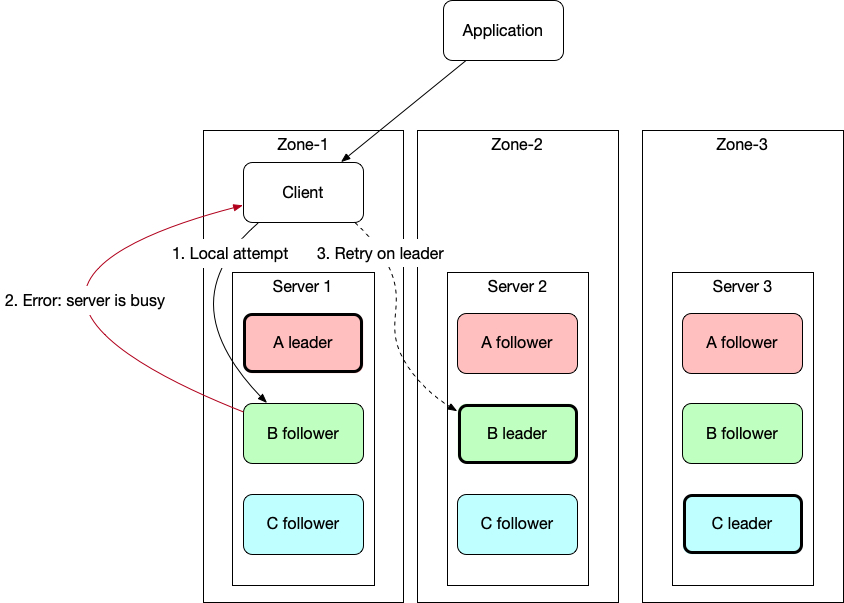
The retry works like:
Simulation
We’ve seen cascading failures in TiKV clusters. So I wrote a simulator to study the robustness of the feature.
The simulation involves an app generating transactions, each containing multiple read requests. Requests are dispatched to three clients and multiple servers (TiKVs) spread across three availability zones (AZs). The process is straightforward: an app’s request is directed to a client, which then forwards it to a server - read requests initially target a local AZ’s follower. If the read fails, the request is escalated first to the leader, then to other followers if necessary. Should all replicas fail, the error is relayed back to the app. Each server has a FIFO queue to handle requests.
The model incorporates two timeout mechanisms:
- A configurable KV read timeout, enforced by the server, is set at one second and applies only to the initial round of attempts of each request. If a timeout occurs, the request may be retried on alternative peers. This is the feature I wanted to study.
- A maximum execution time, monitored by the client, defines the total duration a request can take from the App’s viewpoint, inclusive of any internal retries. If this limit is exceeded, a timeout error is reported back to the App.
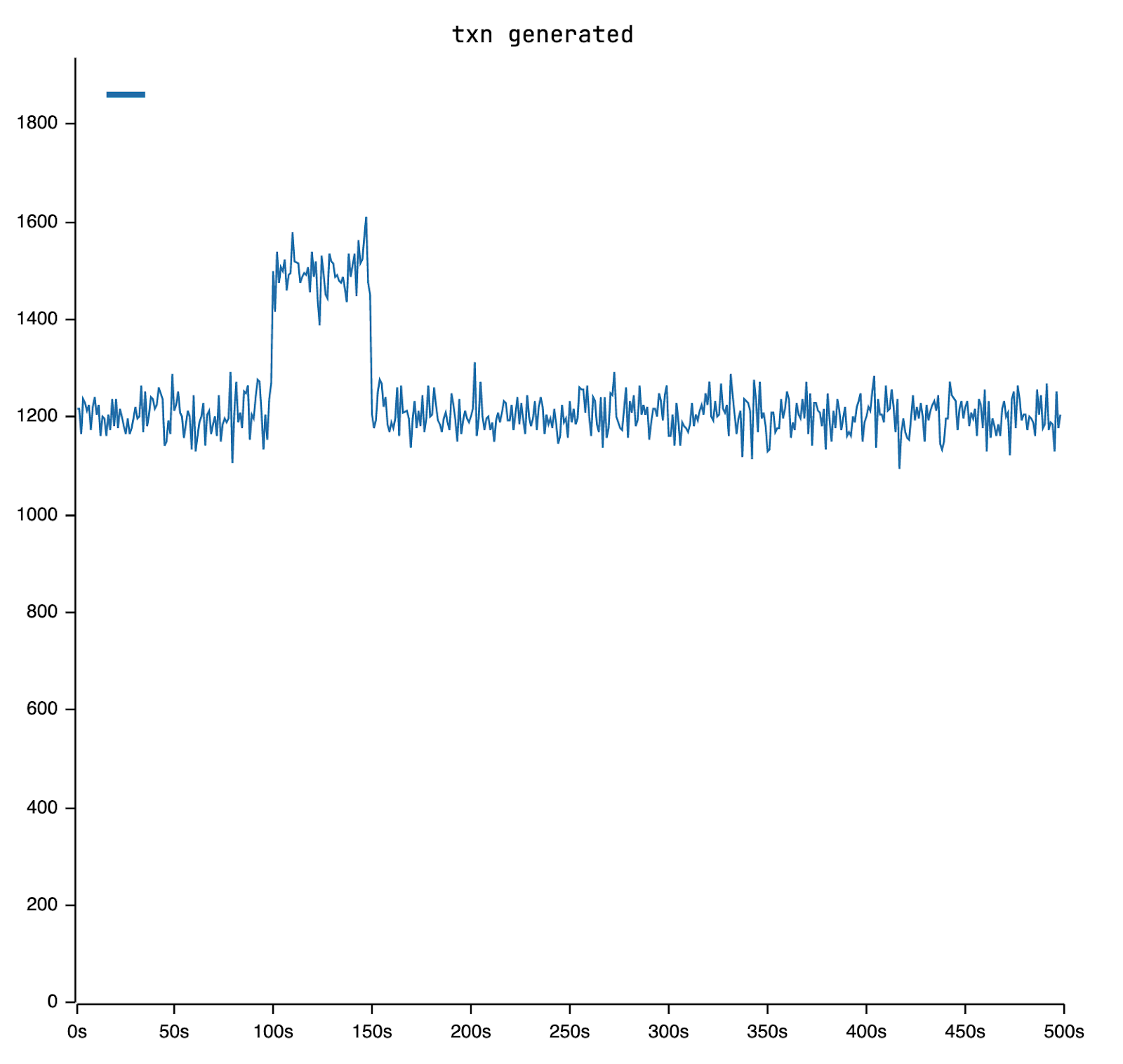
The simulation has a duration of 500 seconds. During the interval from the 100th to the 150th second, the App is permitted to produce a workload that is 1.25 times its standard load.
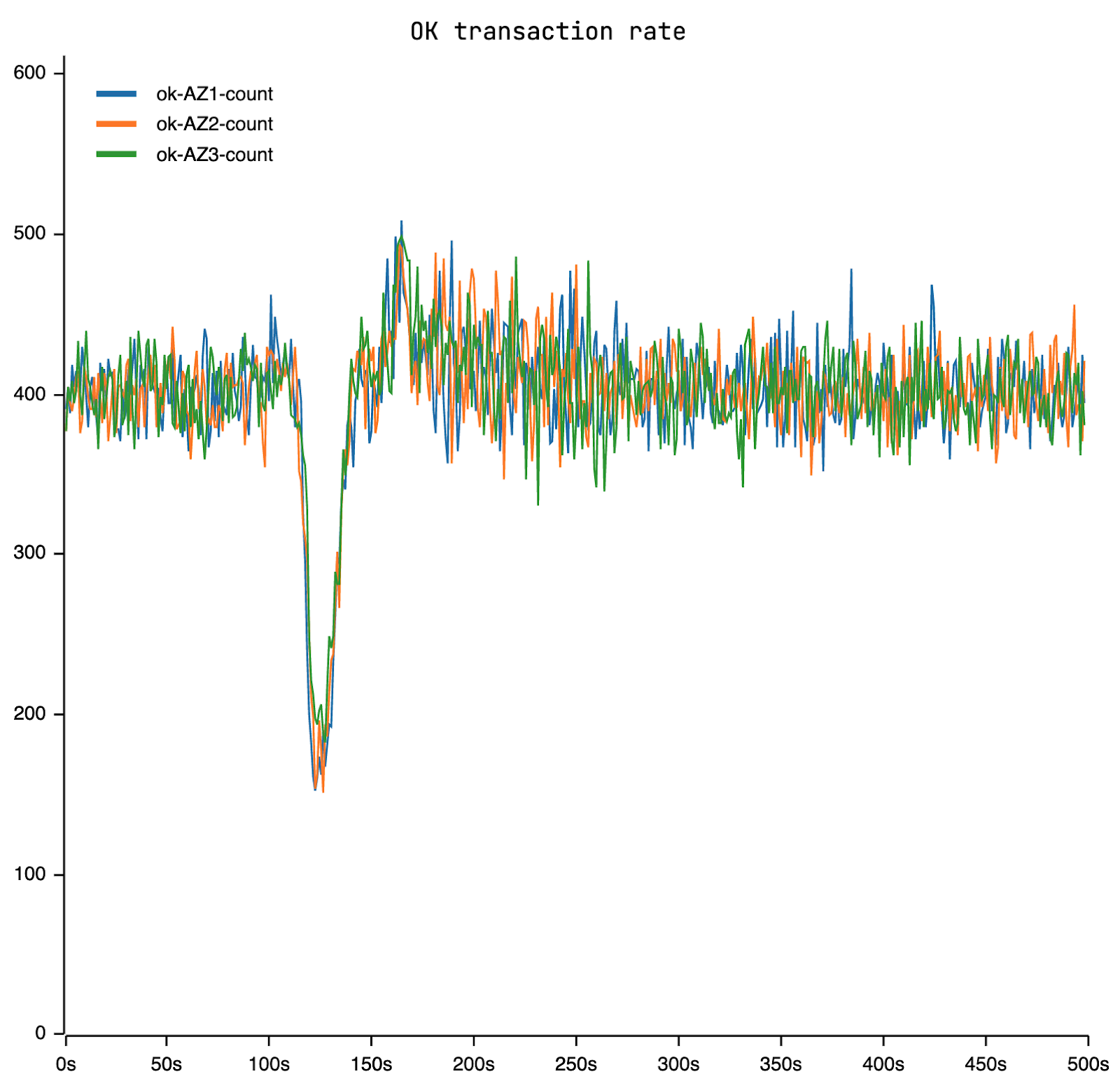
The throughput experiences some fluctuation due to the load spike, but stabilizes once the spike disappears. Throughout this period, no errors are reported back to the App.
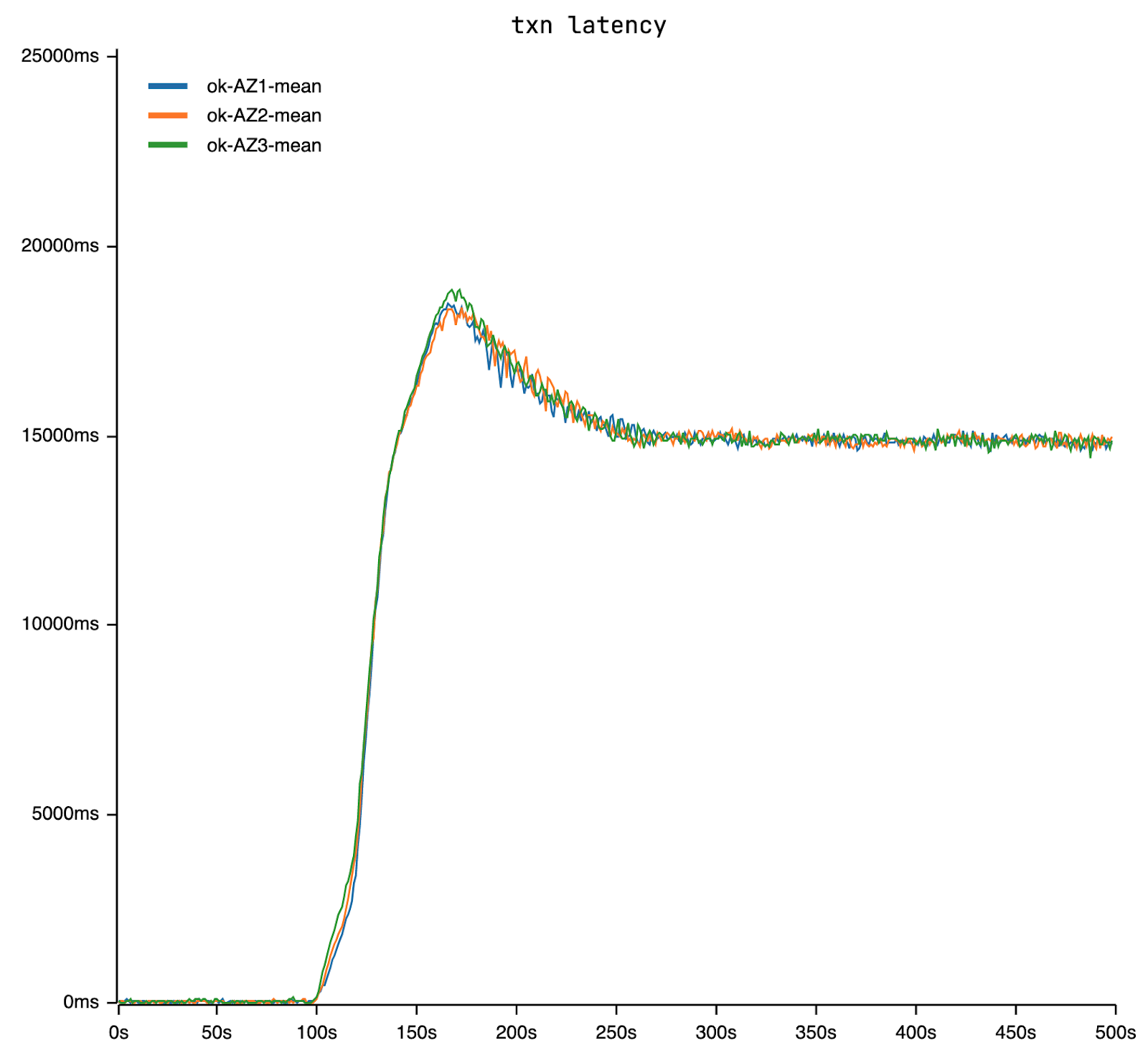
Post-spike transaction latency stabilizes at an level of approximately 15 seconds, significantly higher than the pre-spike tens of milliseconds, suggesting the cluster transitions into a metastable state.
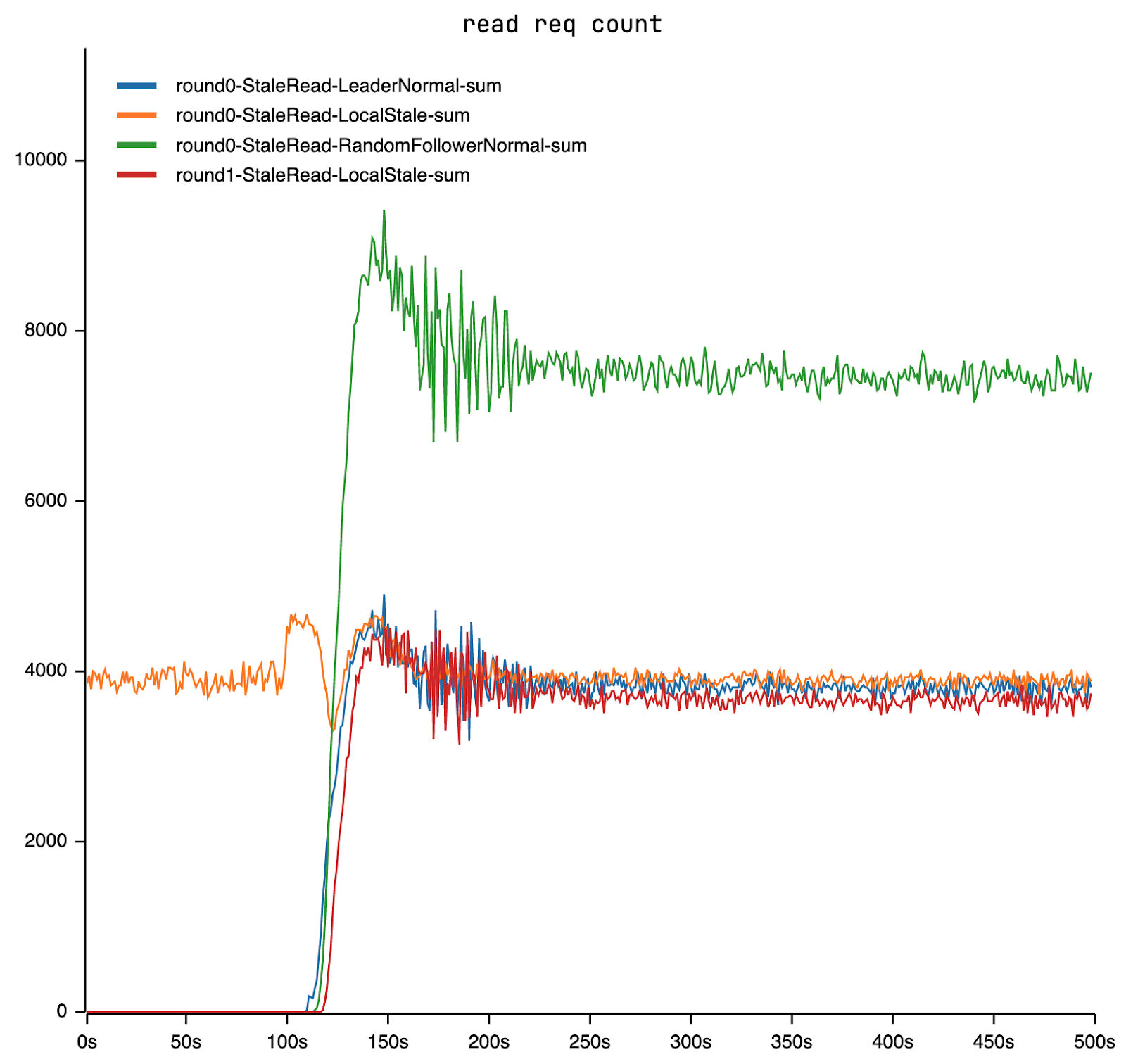
Investigating the cause of this phenomenon involved analyzing server-side QPS, indicating sustained high pressure post-spike. Initial round requests predominantly fail across the sequence: local -> leader -> followers x2. Subsequent local requests in the second round, without the configurable read timeout, succeed. The extra load comes from retries. Retries come from read timeouts.
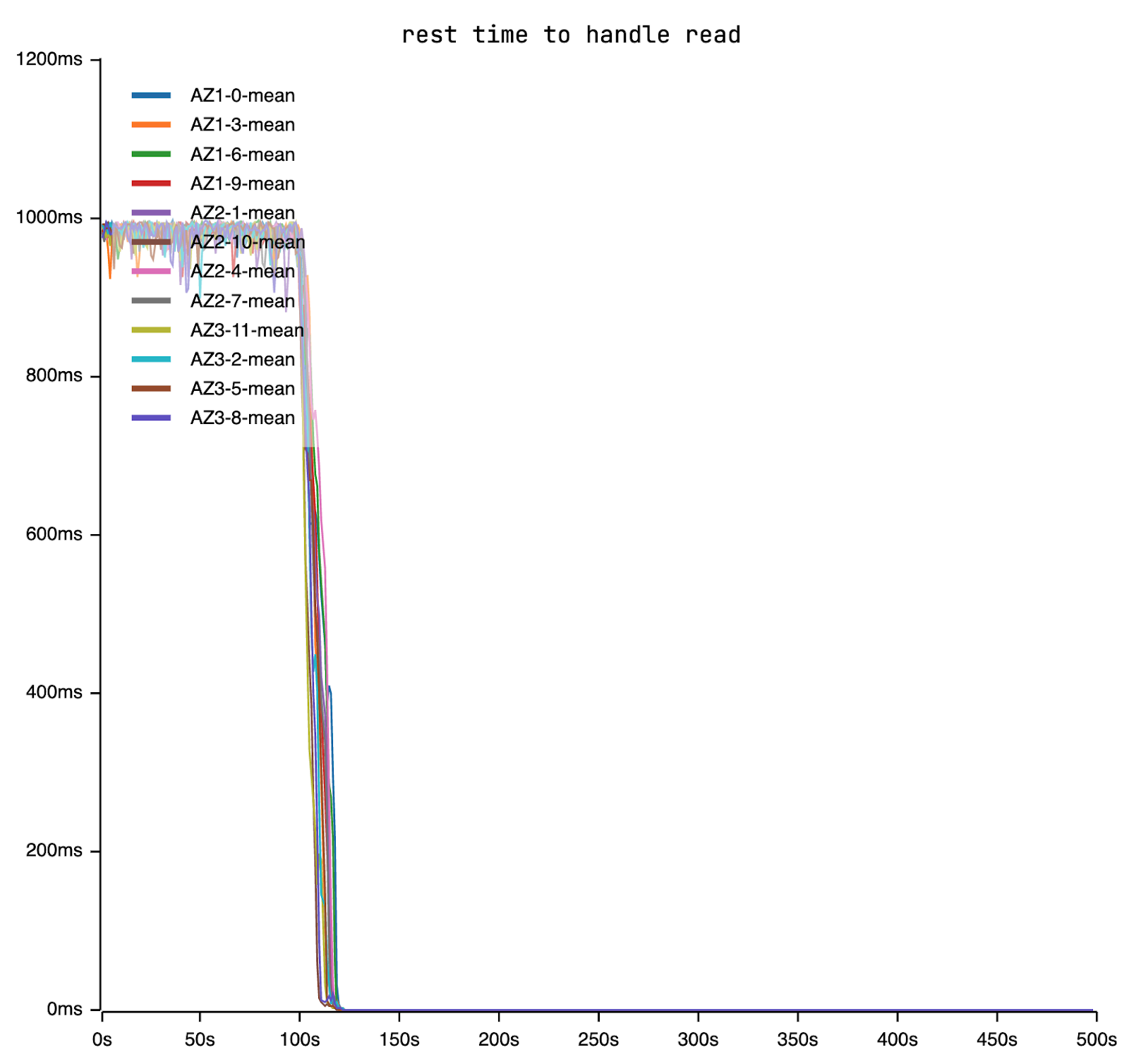
Read requests often time out as there’s a high likelihood that a request, once removed from the queue, will not complete its task within the deadline.
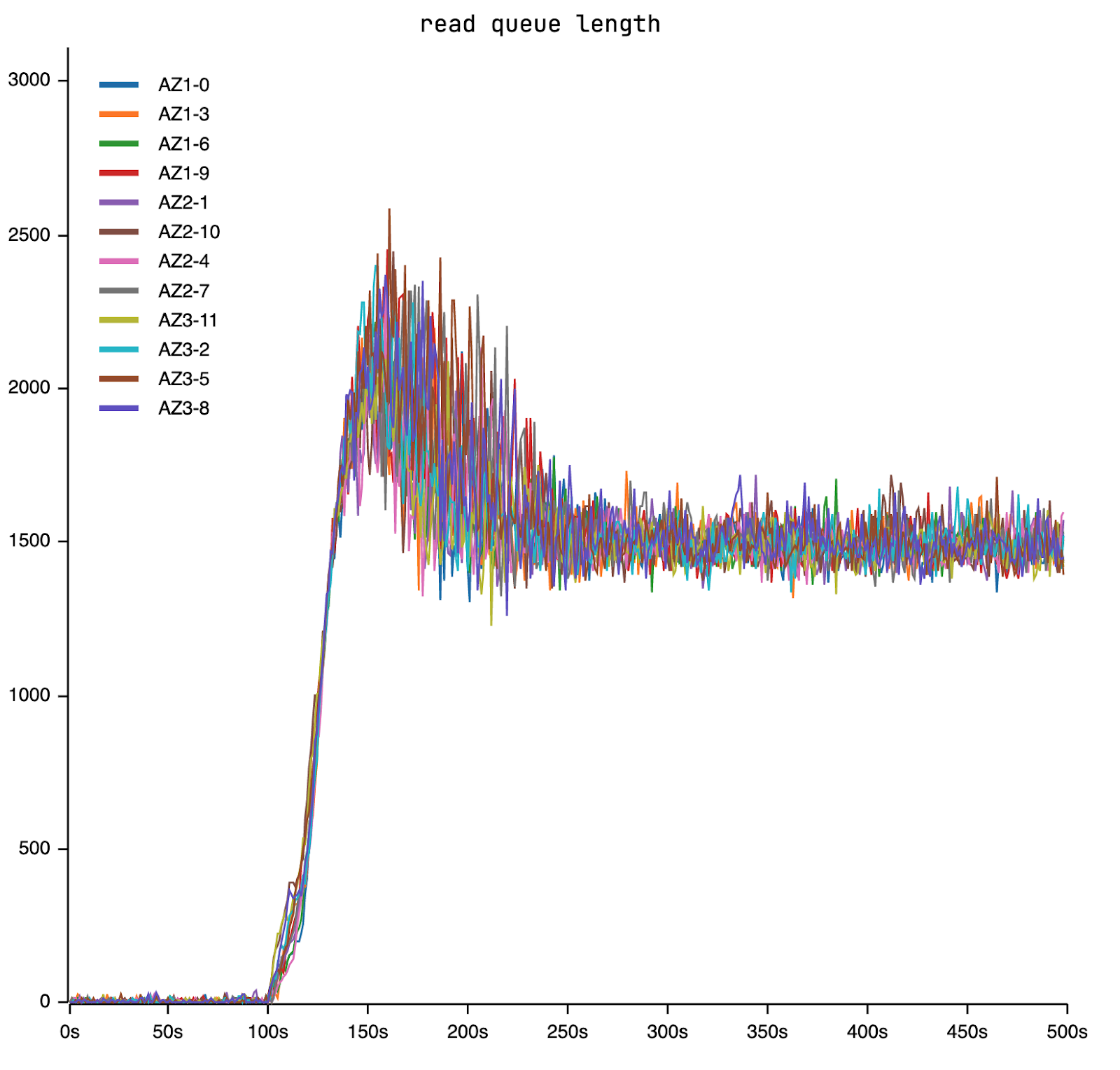
And that is because the read task queue is too long.
In summary, the load spike leads to an overload in TiKV’s readpool due to the accumulation of read tasks in the queue. After the spike subsides, the prolonged queue causes tasks to frequently time out, and subsequent retries maintain the overloaded state of TiKV. This situation does not automatically resolve.
Increasing load and decreasing system capacity is identical in this situation. In further simulation, it turned out the metastable state can also be triggered by IO latency spikes.
Take-aways
I found more materials discussing the problem:
- http://muratbuffalo.blogspot.com/2023/09/metastable-failures-in-wild.html
- https://sigops.org/s/conferences/hotos/2021/papers/hotos21-s11-bronson.pdf
- https://www.usenix.org/conference/osdi22/presentation/huang-lexiang
These great materials already discussed the pattern pretty well in a systematic way. I’ll just put some of my personal take-aways here
- Simulator is a useful too to study system behavior. And it’s interesting
- Metastable failure is a result of a tradeoff between efficiency and vulnerability. Higher resouce utilization causes higher overloading risk.
- This can be addressed from either perspective:
- Triggers. You can hardly eliminate triggers like IO spike and load spike. But you can be prepared for it.
- Sustaining effects. Be careful and think twice before applying a feature that could possibly amplify system load.
